在當(dāng)今快速演進(jìn)的數(shù)字時(shí)代,后端開(kāi)發(fā)中的數(shù)據(jù)存儲(chǔ)與處理已不再是單一技術(shù)的選擇,而是根據(jù)應(yīng)用場(chǎng)景、數(shù)據(jù)特性及業(yè)務(wù)需求進(jìn)行精細(xì)化組合的策略。現(xiàn)代后端架構(gòu)中,數(shù)據(jù)庫(kù)與數(shù)據(jù)處理服務(wù)呈現(xiàn)出多元化、專(zhuān)業(yè)化與云原生的鮮明特征。
一、關(guān)系型數(shù)據(jù)庫(kù):事務(wù)與一致性的基石
關(guān)系型數(shù)據(jù)庫(kù)(RDBMS)憑借其ACID事務(wù)特性、強(qiáng)大的SQL查詢(xún)能力及成熟的數(shù)據(jù)模型,依然是許多核心業(yè)務(wù)系統(tǒng)的首選。
- MySQL / PostgreSQL:作為開(kāi)源領(lǐng)域的雙雄,它們?cè)诟咝阅堋⒖煽啃院拓S富的功能集(如PostgreSQL對(duì)JSON、地理空間數(shù)據(jù)的原生支持)上持續(xù)演進(jìn),廣泛應(yīng)用于Web應(yīng)用、企業(yè)軟件。
- 云托管服務(wù):AWS RDS、Google Cloud SQL、Azure Database for PostgreSQL/MySQL等,提供了自動(dòng)備份、擴(kuò)縮容、高可用等管理功能,極大降低了運(yùn)維復(fù)雜度。
- 商業(yè)數(shù)據(jù)庫(kù):Oracle、Microsoft SQL Server在大型企業(yè)、金融機(jī)構(gòu)中仍占據(jù)重要地位,尤其在需要復(fù)雜事務(wù)處理和歷史包袱重的系統(tǒng)中。
二、NoSQL數(shù)據(jù)庫(kù):應(yīng)對(duì)多樣化數(shù)據(jù)模型與規(guī)模
為應(yīng)對(duì)海量數(shù)據(jù)、高并發(fā)、靈活模式等挑戰(zhàn),NoSQL數(shù)據(jù)庫(kù)成為關(guān)鍵補(bǔ)充。
- 文檔數(shù)據(jù)庫(kù):如MongoDB,以JSON-like格式存儲(chǔ)數(shù)據(jù),模式靈活,適合內(nèi)容管理、產(chǎn)品目錄等場(chǎng)景。其云服務(wù)Atlas提供了全球分布、自動(dòng)分片等能力。
- 寬列存儲(chǔ):如Apache Cassandra、ScyllaDB,擅長(zhǎng)寫(xiě)入密集型負(fù)載和跨地域復(fù)制,常用于時(shí)序數(shù)據(jù)、消息傳遞等。云服務(wù)如AWS Keyspaces提供了托管版本。
- 鍵值存儲(chǔ):如Redis(內(nèi)存存儲(chǔ),用于緩存、會(huì)話存儲(chǔ)、實(shí)時(shí)排行榜)、Amazon DynamoDB(全托管,提供單毫秒級(jí)延遲,適用于高吞吐應(yīng)用)。
- 圖數(shù)據(jù)庫(kù):如Neo4j、Amazon Neptune,專(zhuān)為處理高度互聯(lián)數(shù)據(jù)設(shè)計(jì),廣泛應(yīng)用于社交網(wǎng)絡(luò)、推薦系統(tǒng)、欺詐檢測(cè)。
三、數(shù)據(jù)倉(cāng)庫(kù)與湖倉(cāng)一體:分析與智能的引擎
對(duì)于大規(guī)模數(shù)據(jù)分析、商業(yè)智能(BI)和機(jī)器學(xué)習(xí),專(zhuān)用系統(tǒng)不可或缺。
- 云數(shù)據(jù)倉(cāng)庫(kù):Snowflake(獨(dú)立于云廠商,計(jì)算存儲(chǔ)分離)、Google BigQuery(無(wú)服務(wù)器,強(qiáng)于即席查詢(xún))、Amazon Redshift(列式存儲(chǔ),深度集成AWS生態(tài))是主流選擇,支持PB級(jí)數(shù)據(jù)分析。
- 數(shù)據(jù)湖:如基于Amazon S3、Azure Data Lake Storage的對(duì)象存儲(chǔ),用于存儲(chǔ)原始格式的龐大數(shù)據(jù)集,常與Apache Spark、Presto/Trino等計(jì)算引擎結(jié)合。
- 湖倉(cāng)一體:Databricks Lakehouse、AWS Lake Formation等架構(gòu),試圖融合數(shù)據(jù)湖的靈活性與數(shù)據(jù)倉(cāng)庫(kù)的管理分析能力。
四、實(shí)時(shí)數(shù)據(jù)處理與流式存儲(chǔ)
物聯(lián)網(wǎng)、實(shí)時(shí)監(jiān)控、事件驅(qū)動(dòng)架構(gòu)的興起,推動(dòng)了流式數(shù)據(jù)棧的普及。
- 消息隊(duì)列與流平臺(tái):Apache Kafka已成為實(shí)時(shí)數(shù)據(jù)管道的標(biāo)準(zhǔn),用于事件流、日志聚合;其云服務(wù)如Confluent Cloud、AWS MSK提供了托管方案。
- 流式數(shù)據(jù)庫(kù):如Apache Flink(流處理引擎,支持復(fù)雜事件處理)、Materialize(基于增量計(jì)算提供實(shí)時(shí)物化視圖)。
五、新興趨勢(shì)與多模型數(shù)據(jù)庫(kù)
- 云原生數(shù)據(jù)庫(kù):如CockroachDB(分布式SQL,強(qiáng)一致性)、Google Cloud Spanner(全球分布式,兼具SQL與水平擴(kuò)展),解決了傳統(tǒng)RDBMS擴(kuò)展難的問(wèn)題。
- 多模型數(shù)據(jù)庫(kù):如Azure Cosmos DB、FaunaDB,在一個(gè)數(shù)據(jù)庫(kù)中支持文檔、圖、鍵值等多種數(shù)據(jù)模型,通過(guò)統(tǒng)一接口簡(jiǎn)化架構(gòu)。
- Serverless數(shù)據(jù)庫(kù):如AWS Aurora Serverless、Google Firestore,根據(jù)負(fù)載自動(dòng)擴(kuò)縮容,實(shí)現(xiàn)了真正的按使用量付費(fèi),適合波動(dòng)性大的工作負(fù)載。
六、數(shù)據(jù)處理與存儲(chǔ)服務(wù)的選擇策略
后端架構(gòu)師在選擇時(shí)需綜合考量:
- 數(shù)據(jù)模型與查詢(xún)模式:結(jié)構(gòu)化還是半結(jié)構(gòu)化?需要復(fù)雜關(guān)聯(lián)還是簡(jiǎn)單查詢(xún)?
- 一致性要求:強(qiáng)一致性還是最終一致性?
- 規(guī)模與性能:數(shù)據(jù)量、讀寫(xiě)吞吐、延遲敏感度。
- 運(yùn)維成本:團(tuán)隊(duì)技能、托管服務(wù) vs 自托管。
- 生態(tài)集成:與現(xiàn)有云服務(wù)、工具鏈的兼容性。
現(xiàn)代后端數(shù)據(jù)棧常采用多數(shù)據(jù)庫(kù)混合架構(gòu)(Polyglot Persistence),例如核心業(yè)務(wù)用PostgreSQL保證事務(wù),用戶(hù)會(huì)話用Redis加速,分析用Snowflake,日志流用Kafka。全托管云服務(wù)正成為主流,使團(tuán)隊(duì)能更聚焦于業(yè)務(wù)邏輯而非基礎(chǔ)設(shè)施管理。
后端的數(shù)據(jù)庫(kù)與數(shù)據(jù)處理生態(tài)正朝著專(zhuān)業(yè)化、云化、智能化的方向快速發(fā)展。理解各類(lèi)工具的核心優(yōu)勢(shì)與適用場(chǎng)景,并根據(jù)實(shí)際需求進(jìn)行合理選型與組合,是構(gòu)建高效、可靠、可擴(kuò)展后端系統(tǒng)的關(guān)鍵。

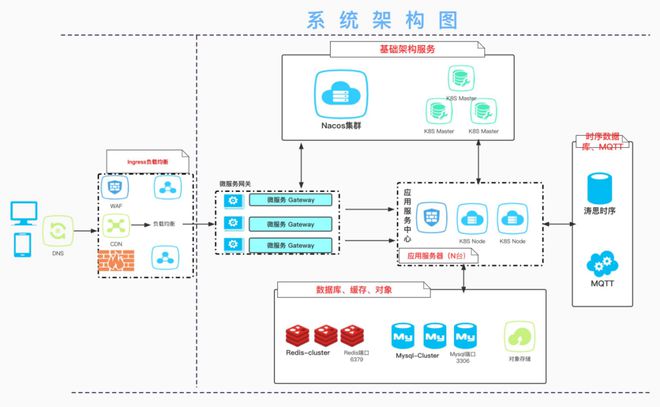
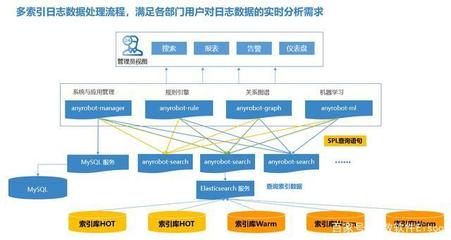


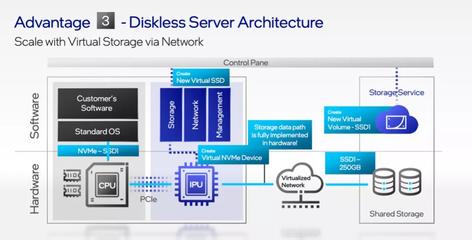
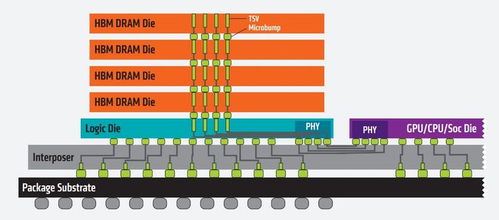 AI服務(wù)器需求引爆HBM市場(chǎng) 海外大廠訂單激增價(jià)格暴漲,產(chǎn)業(yè)鏈?zhǔn)芤嫔鲜泄臼崂?/span>
AI服務(wù)器需求引爆HBM市場(chǎng) 海外大廠訂單激增價(jià)格暴漲,產(chǎn)業(yè)鏈?zhǔn)芤嫔鲜泄臼崂?/span>