引言
在當今大數據時代,高效的數據存儲與處理技術是企業數字化轉型的核心驅動力。Hadoop作為開源分布式計算框架的基石,以其高容錯性、高擴展性和低成本優勢,成為處理海量數據的首選方案。CSDN(中國開發者網絡)作為國內領先的IT技術社區和綜合服務平臺,其背后龐大的用戶行為數據、內容數據及交互數據的管理,離不開對Hadoop技術的深度應用。本文將系統闡述Hadoop的數據存儲與處理核心流程,并結合CSDN的實際應用場景,探討其數據處理與存儲服務的實踐。
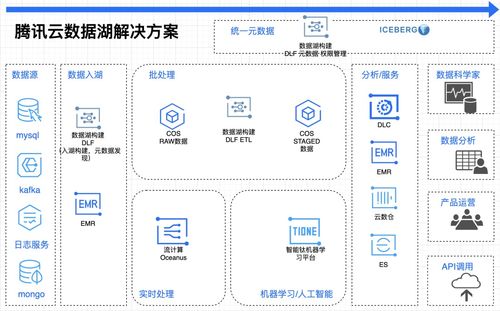
第一部分:Hadoop數據存儲流程
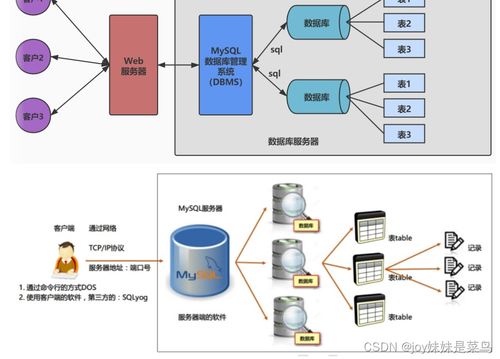
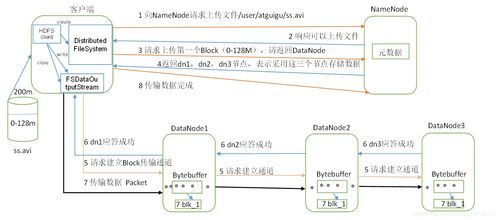
Hadoop的數據存儲主要由其分布式文件系統——HDFS(Hadoop Distributed File System)完成。其設計目標是存儲超大規模數據集,并在商用硬件集群上提供高吞吐量的數據訪問。
核心流程如下:
1. 文件分塊: 當客戶端上傳一個文件時,HDFS首先將其切分為固定大小的數據塊(Block,默認128MB或256MB)。分塊存儲便于并行處理、簡化存儲管理并適應大規模數據。
2. 元數據管理: 由NameNode負責管理文件系統的命名空間(如目錄樹、文件到數據塊的映射)以及數據塊在集群中的位置信息。這些信息(即元數據)常駐內存以保證快速訪問。
3. 數據寫入與復制:
* 客戶端與NameNode通信,獲取可寫入的數據節點(DataNode)列表。
- 客戶端將數據塊直接寫入列表中的第一個DataNode,該節點接收數據的會將其流水線式地復制到列表中的其他節點,默認創建3個副本。
- 這種多副本機制是HDFS實現容錯和高可靠性的關鍵,確保部分硬件失效時數據不丟失。
- 數據存儲與心跳維護: DataNode將數據塊以本地文件的形式存儲在磁盤上,并定期向NameNode發送心跳信號和數據塊報告,以確認其存活狀態及存儲的數據塊列表。
流程特點: 寫一次、讀多次;移動計算而非移動數據(將計算任務分發到數據所在節點)。
第二部分:Hadoop數據處理流程
數據處理主要由MapReduce計算模型完成,它將復雜的分布式計算抽象為Map和Reduce兩個核心階段。
核心流程如下:
1. 輸入與分片: 輸入數據(通常來自HDFS)被邏輯切分為多個輸入分片。每個分片由一個Map任務處理,分片大小通常與HDFS的數據塊大小一致,以實現數據本地化計算。
2. Map階段:
* 每個Map任務讀取一個輸入分片,并逐條調用用戶定義的map()函數。
map()函數處理輸入的鍵值對,并輸出一系列中間鍵值對。這些中間結果首先被寫入內存緩沖區。
- Shuffle與Sort階段(關鍵橋梁):
- 當緩沖區達到閾值,數據會被溢寫到本地磁盤,并在寫入前根據中間鍵進行分區(決定由哪個
Reduce任務處理)和排序。
- 所有
Map任務完成后,每個Reduce任務通過HTTP協議從各個Map任務的磁盤上拉取屬于自己的那部分分區數據,這個過程稱為Shuffle。
Reduce任務將拉取到的數據進行歸并排序,使得相同鍵的記錄聚集在一起。
- Reduce階段: 排序后的中間數據被輸入到用戶定義的
reduce()函數中。reduce()函數對每個鍵及其關聯的值列表進行處理,并產生最終的輸出結果。 - 輸出: 最終的輸出結果被寫入HDFS,通常每個
Reduce任務生成一個獨立的輸出文件。
流程特點: 批處理、高吞吐量;通過Shuffle階段實現數據的重新分發與聚合。
第三部分:CSDN的數據處理和存儲服務實踐
CSDN平臺承載著數千萬開發者的技術博文、問答、課程、動態等海量非結構化與半結構化數據。其數據處理與存儲服務深度集成了Hadoop生態系統。
1. 數據存儲服務:
原始數據湖: 利用HDFS構建企業級數據湖,統一存儲來自Web服務器、App、日志系統等各類原始數據(如用戶點擊流、內容發布記錄、搜索日志)。HDFS的廉價擴展能力完美支撐了CSDN數據量的持續快速增長。
結構化數據倉庫: 在HDFS之上,通過Hive或Spark SQL建立數據倉庫,將原始日志進行ETL清洗和轉換后,以結構化的表形式存儲,支撐BI報表、用戶畫像分析等下游應用。
2. 數據處理服務:
離線批量處理: 對于用戶行為分析、內容質量統計、個性化推薦模型的離線訓練等延遲不敏感的任務,CSDN使用MapReduce或更高效的Spark引擎進行每日/每周的批量計算。例如,通過處理前一天的日志,計算熱門技術話題排行榜。
實時數據處理: 對于監控告警、實時推薦、動態流更新等低延遲場景,CSDN會結合使用Storm、Flink或Spark Streaming等流處理框架,它們可與Hadoop生態無縫集成,從Kafka等消息隊列中消費數據,進行實時處理后將結果存入HBase或HDFS。
* 數據挖掘與機器學習: 基于存儲在HDFS上的海量歷史數據,利用Mahout或Spark MLlib等分布式機器學習庫,進行社區熱點發現、用戶聚類、內容自動分類等復雜分析,驅動產品智能化。
結論
Hadoop通過HDFS和MapReduce等核心組件,定義了經典的大數據存儲與批處理范式。其清晰的存儲流程(分塊-復制-分布式存儲)與處理流程(分片-Map-Shuffle-Reduce)為處理PB級數據提供了可擴展且可靠的解決方案。在CSDN這樣的實際業務平臺中,Hadoop已不僅僅是單一工具,而是演變為其大數據基礎設施的核心。CSDN通過將Hadoop與生態系統中其他工具(如Hive、Spark、HBase)有機結合,構建了一套從數據攝入、存儲、批量處理到實時計算和智能分析的全鏈路數據處理與存儲服務體系,從而有效地將數據資產轉化為產品價值與用戶體驗,服務廣大開發者社區。
隨著云原生和實時化趨勢的發展,Hadoop生態也在不斷演進(如YARN資源調度、容器化部署),但其核心的分布式思想與流程,依然是構建大型數據處理系統的寶貴藍圖。